If you’re building or analysing a sports simulation system, there’s an important principle that often gets overlooked:
Just because something is extremely unlikely doesn’t mean it’s impossible.
And in the NFL, nothing illustrates that better than the 2–0 final score.
Why 2–0 Is So Special
Most NFL games involve multiple scoring plays: touchdowns, field goals, extra points, maybe the occasional safety.
But a 2–0 game requires something very specific.
The only scoring play in the entire game must be a safety.
That means:
• No touchdowns
• No field goals
• No extra points
• No two-point conversions
• Just one safety, and nothing else
Given modern offences, kicking ranges, analytics-driven play calling, and rules designed to increase scoring, that outcome is almost absurdly rare.
But it has happened.
A Quick Stat Box
Rarest NFL Final Score: 2–0
Total occurrences: 5 games
Last time it happened: 18 September 1938
Years since the last 2–0 game: 87 years
Teams involved in the most recent game: Chicago Bears vs Green Bay Packers
Winning score came from: A single safety
In other words, the rarest possible realistic NFL score happened before World War II.
Every 2–0 Game in NFL History
There have only been five such games in the entire history of the league.
Date
Winner
Loser
Nov 29, 1923
Akron Pros
Buffalo All-Americans
Nov 21, 1926
Kansas City Cowboys
Buffalo Rangers
Nov 29, 1928
Frankford Yellow Jackets
Green Bay Packers
Oct 16, 1932
Green Bay Packers
Chicago Bears
Sep 18, 1938
Chicago Bears
Green Bay Packers
The last time it happened was 1938.
That means it has been 87 years since the NFL saw a 2–0 final score.
The Bears Connection
As a Chicago Bears fan, I find this statistic especially entertaining.
The Bears appear twice in the list.
• Losing 2–0 to the Packers in 1932
• Winning 2–0 against the Packers in 1938
If you’re going to have bizarre historical trivia, doing it against your biggest rival feels about right.
Somewhere in the long, strange history of the Chicago Bears vs the Green Bay Packers rivalry, there’s a game where the entire scoreboard was produced by a single safety.
The Simulation Lesson
If you build sports simulations (which I spend a lot of time thinking about), the takeaway is simple.
When you model a sport, you usually focus on the most likely outcomes.
But the edge cases matter too.
A 2–0 result is incredibly unlikely, but it’s not impossible. It has happened. Multiple times.
So if you’re simulating NFL games, you should always sanity-check your model:
• Does the simulation allow a safety as the only score?
• Could the game realistically end 2–0?
If the answer is no, your model might be accidentally removing real outcomes from the game.
Even the weird ones.
And sometimes the weird ones are the most interesting.….
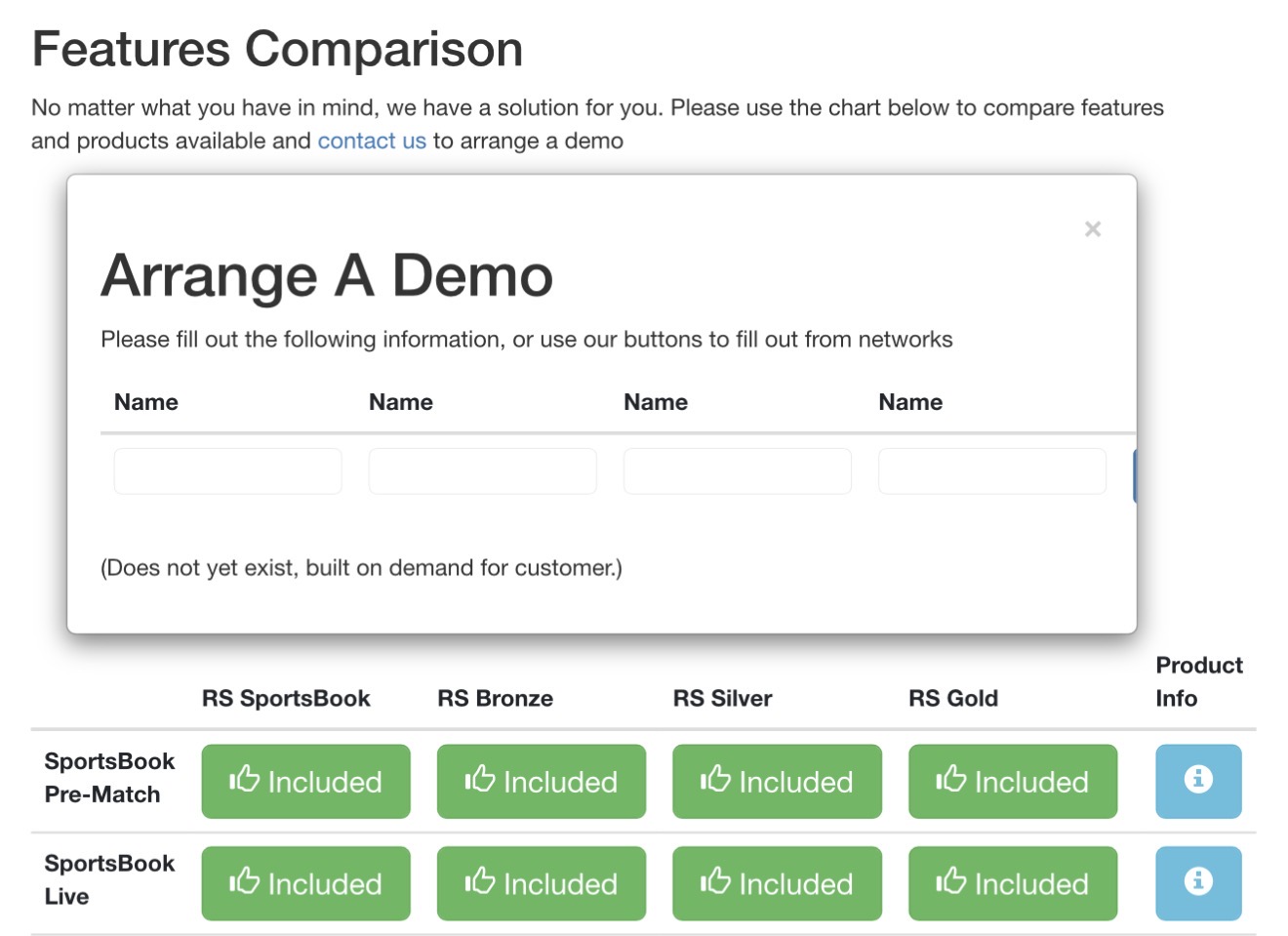
It was two static html pages – maybe I should have added some server side stuff, maybe if I did it again I would.
It probably took me around 20 minutes to do it overall.
On the dialog, it says “does not yet exist” – that’s a big lesson, right? Next time – didn’t matter if it was a quick demo or less – I learned to add more polish – take that few extra minutes to really sell it.
It was flat html, some simple jquery and some basic css.
To be fair, I wish now that AI and cursor was a thing back then!
Screenshot
If you’re interested, here’s a ZIP of the demo so you can admire the truly questionable CSS for yourself:
Over the years I’ve registered various domains for random ideas and experiments. Some went nowhere. Most were cheap. All were forgettable.
pstars-test.info – at the time it seemed like a good idea for our table fussball league at work (and .info was cheap for one year). We never used it in the end.
cpt-tech-dev.online – we created simple “A” DNS records on this to make it easier to remember internal servers. It cost about £1.99. Not exciting, but effective and no files were ever hosted or uploaded. A waste, probably!
speakeasydating.com – a friend wanted to build a speed dating site when we were single and carefree. We never got round to it. Shame really, could’ve been cool, right?
I suppose it’s best to have more of a concrete plan before registering domains, these days I’m a bit less gung-ho on that, even it is only 1.99. Maybe because I’m too busy buying shiny things, but I think I have learned from those earlier days. Only buy it if you really need it, and if you’re gonna use it right away.
Although. AirPods Max. Damn.
Anyway – that’s the full story, and perhaps a lesson or two into the bargain when doing a demo or buying domains.
Like most sensible people in 2026, I now outsource part of my thinking to a large, polite, and slightly unsettling machine that lives in my phone.
It helps me draft emails, sanity-check arguments, stress-test decisions, and occasionally talk me out of writing things on LinkedIn that would definitely have required a follow-up apology.
So, in a moment of either courage or poor judgement, I asked it a dangerous question:
“Based on our conversations… what do you think I’m actually like?”
This is a bit like asking your GP to be honest, your lawyer to be poetic, and your mirror to stop being polite.
What came back was… uncomfortably accurate.
Here’s the human translation.
Apparently, I’m “Systems-First” (Which Is a Polite Way of Saying “Boring”)
One of the first things it called out is that I don’t really believe in vibes-based engineering.
I don’t get excited by:
Demo theatre
Slideware architecture
“AI, but with more AI”
I do get excited by:
Things that survive contact with production
Clear ownership at 3am
Boring systems that keep regulators, boards, and sleep schedules happy
If you tell me something is “strategic,” my reflex is to ask:
“Great. Who runs it? How does it fail? How do we know it’s broken? And how much does it cost when it does?”
Which is not how you win friends at innovation workshops, but it is how you avoid explaining outages to a board.
The AI’s verdict: I optimise for operational truth over narrative comfort.
Honestly, that should probably be on my business card.
I Apparently Care a Lot About How Things Land (Not Just What They Say)
This one stung a bit, because it’s true.
I spend a lot of time thinking about:
How a CEO will read something
How legal will read it
How engineers will read it
How LinkedIn will absolutely, definitely read it in the worst possible way
If you’ve ever seen me iterate a “simple” message five times, this is why.
It’s not indecision. It’s blast-radius management.
Words have consequences in regulated, political, or high-stakes environments. I’ve learned (sometimes the hard way) that being technically right and being organisationally effective are not the same thing.
The AI described me as a “high-context communicator.”
I prefer my own term: professionally paranoid.
Leadership, Apparently: I’m a “Stabiliser”
This bit was actually reassuring.
The machine reckons my default leadership mode is:
Clarify ownership
Define boundaries
Put governance where chaos wants to live
Make escalation paths boring and predictable
Replace heroics with systems
Which, in human terms, means I’m the person who turns up after things have been on fire and says:
“Right. Let’s make sure this never requires a hero again.”
I care deeply about:
Decision rights
RACI
L1/L2/L3 models
Runbooks
“No surprises” cultures
Not because I love process (I don’t), but because process is cheaper than panic.
If you’ve worked in regulated or high-consequence tech, you’ll know exactly why this matters.
My Risk Profile Is… Weirdly Split
This was one of the more interesting bits.
On systems and operations, I’m conservative:
Guardrails
Gates
Controls
Evidence
Auditability
“Prove it works before we bet the company on it”
On truth and narrative, I’m much less conservative:
I’ll challenge stories I think are wrong
I’ll push back on things that don’t survive scrutiny
I’m willing to absorb some political discomfort if the alternative is organisational self-deception
In other words:
I hate operational risk
I tolerate personal risk
I really dislike lying to ourselves
Which probably explains most of my career, in hindsight.
What I Do Under Stress (Spoiler: I Make More Lists)
According to my AI-powered psychological ambush, when pressure goes up, I tend to:
Add more structure
Break problems into phases
Build frameworks
Stress-test narratives
Rewrite important messages until they either land safely or I lose the will to live
This is, apparently, my coping mechanism: turn ambiguity into diagrams.
There are worse habits.
The downside is that you can over-polish, over-analyse, or try to engineer uncertainty out of human systems (which is, frankly, optimistic).
The upside is that you usually don’t wake up to surprises you could have designed out.
How This Apparently Comes Across
This was the bit I was most curious about.
To boards and CEOs:
“Safe pair of hands. Sees around corners. Not a hype merchant.”
To engineers:
“Protects us from chaos. Clear about ownership. Understands production reality.”
To recruiters and peers:
“Operational CTO. Platform stabiliser. Good in regulated or high-blast-radius environments.”
Also, occasionally:
“Possibly over-indexed on risk and process.”
Which is fair. I’ve seen what happens when you under-index on those things.
The Uncomfortable Summary
The AI boiled me down to something like this:
A systems-oriented, governance-minded, pragmatically stubborn technology leader who prefers boring reliability to exciting failure, and is willing to be unpopular to avoid organisational self-deception.
I’d probably phrase it more simply:
I like tech that works.
I like organisations that know who owns what.
I like fewer surprises.
And I really don’t like pretending.
Should You Ask Your AI What It Thinks of You?
Only if you’re in the mood for a slightly unsettling mirror that:
Doesn’t laugh at your jokes
Remembers everything
And has absolutely no incentive to protect your ego
On the plus side, it’s cheaper than therapy and less likely to prescribe running.
On the downside, it’s annoyingly good at pattern recognition.
Still, I’d recommend it.
Worst case, you learn something.
Best case, you get a blog post out of it.
And if nothing else, it confirms what I’ve suspected for years:
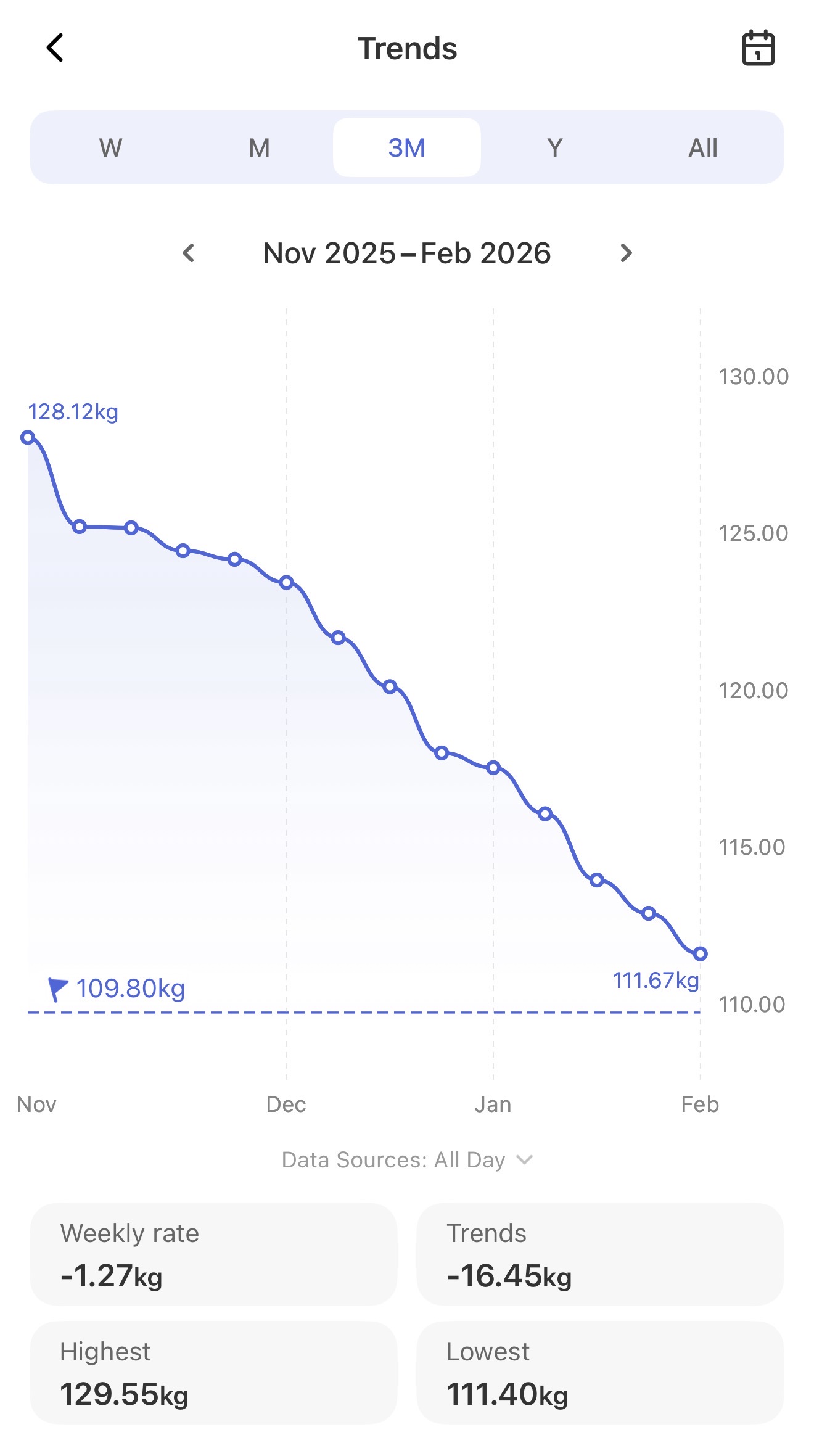
Five months ago, I stepped on the scales and saw a number I’d been expertly pretending didn’t exist: 135kg.
Screenshot
Today, I’m around 112kg. The graph is deeply satisfying in a very nerdy way. It’s just a calm, sensible line trending steadily downwards, to the tune of a bit over 22kg gone in about three or four months.
No drama, no cliff edges, just quiet, consistent progress.
Which, as it turns out, is the good kind.
Yes, I’m on Mounjaro. And yes, it’s been a big part of this. But the biggest surprise hasn’t been the number on the scale. It’s how weirdly… peaceful food has become.
Let’s get the obvious bit out of the way first. Side effects. I’ve been lucky. A bit of nausea here and there, mostly early on, but nothing that’s stopped me living my life or made me regret the decision. When you read some of the stories online, I’m very aware I’ve had a comparatively easy run of it.
The real change has been in my day-to-day behaviour, and more importantly, in my head.
Crisps and random snacking have mostly just… faded out of my life. Fizzy drinks are gone entirely, not because I’m being virtuous, but because I genuinely don’t fancy them anymore. Lunch is often either very light or doesn’t happen at all, simply because I’m not hungry. And as a bonus feature I didn’t order but very much appreciate, the reflux I used to suffer from has improved massively, which I’ll happily blame on eating like a vaguely sensible adult for once.
The strangest part is how quiet food has become. It used to be a constant background process running in my brain. What’s next, what’s in the cupboard, what can I grab quickly. Now it feels more like a polite suggestion than a relentless notification system. I eat when I want to, not because my brain is nagging me like an overenthusiastic product manager.
There’s also a more important change that doesn’t show up on the chart.
I actually feel good about myself again.
Not in a “cue inspirational music and slow-motion jogging” way. More in a calm, slightly surprised, “oh… this is working” way. I’ve still got about 12kg to go before I’m out of the “officially obese” category, which feels like a pretty decent milestone. I’m not done, I’m not claiming victory, and I’m definitely not buying skinny jeans. But for the first time in a long time, this feels achievable rather than theoretical.
And no, before you ask, I’m still not going to the beach. I don’t want to risk them trying to float me back out to sea and fitting me with a tracker. Let’s not tempt fate.
I do want to be very clear about one thing though. I know I’m one of the lucky ones. Not everyone tolerates these meds well. Not everyone gets results like this. Not everyone can access them at all. This isn’t a miracle cure story or a sales pitch. It’s just an honest update from someone who’s finally found something that’s shifted both the numbers and the mindset.
What Mounjaro has really given me isn’t just a smaller appetite. It’s taken away the constant fight with food, made better choices feel easier, turned down the mental noise, and helped me feel more like myself again.
The scale is nice. The graph is very satisfying. But the real win is that food no longer runs the meeting.
I’m not finished yet. But for the first time in years, I’m pretty confident I’m actually going to get there
I haven’t written much about health before, but over the last few months it’s become part of the backdrop of my decision-making — so this feels worth sharing.
A while ago, after a persistent facial rash that worsened with sun exposure, I went through a biopsy. At the time, skin cancer was a genuine concern.
A really good friend of mine from my university days passed away last year from Skin Cancer, so I was very aware of the dangers and it certainly was a big concern.
So when the results came back not cancer, there was real relief — the kind you feel immediately and deeply.
The doctor came to see me as I was getting the stitch taken out, and handed me the report – her first words were re-assuring, important to hear.
”Read this, then come through and see me. Don’t panic – it’s totally manageable, but you’ll need a lot of sun screen….”
That relief was then tempered by a different diagnosis: cutaneous lupus erythematosus (CLE).
CLE is a skin-limited autoimmune condition — not systemic lupus — and in day-to-day terms it’s very manageable. There’s a clear plan, specialist care, and no immediate impact on my ability to work or live fully. But it does come with one very clear and non-negotiable trigger: UV exposure.
That combination of relief and recalibration became a quiet inflection point — the moment we started thinking more deliberately about environment, sustainability, and where we wanted to be long-term.
Living in Australia, that question takes on a particular weight.
Australia’s sunlight is extraordinary — and unforgiving. Even with good sun habits, high-SPF protection, and sensible precautions, the baseline UV exposure here is simply higher than in most parts of the world. For most people, that’s a lifestyle footnote. For someone with a photosensitive autoimmune condition, it becomes a constant background constraint.
None of this is dramatic or debilitating — but it is cumulative. Managing CLE well is about reducing repeated immune activation over time, not “pushing through” flare after flare. Environment plays a role in that, whether we like it or not.
At the same time, this diagnosis prompted some honest reflection. I have a family history of lupus, and while my own condition is different and far milder, it does sharpen your sense of perspective. You start asking quieter questions about sustainability, stress, proximity to support, and what you want the next phase of life to look like.
That combination — health management, environment, and family — ultimately fed into a broader decision my wife and I were already circling: to return to the UK.
This isn’t a reaction, and it isn’t fear-driven. It’s a deliberate choice to put ourselves in an environment that makes long-term health management simpler, not harder — lower ambient UV, easier moderation, and closer proximity to family.
Australia has been an incredible chapter. We’ve built memories here that will always matter. But sometimes the most adult decision is recognising when a place that’s wonderful isn’t the right place anymore.
I’m sharing this not for sympathy, but for completeness. Health doesn’t always arrive as a crisis — sometimes it arrives as information, and what matters is what you do with it.
For me, it’s meant choosing an environment that works with me, not against me.
Bet placement is the most latency-sensitive, revenue-critical, and failure-prone path in any iGaming platform. It sits at the intersection of customer experience, trading risk, regulatory control, and real-time data churn. When it fails, it fails loudly – often under peak load, with money on the line, and very little tolerance for excuses.
What’s interesting is that bet placement failures are rarely caused by a single “bug”. They are almost always the result of architectural tension: too many responsibilities, unclear boundaries, or optimistic assumptions about dependency behaviour.
Below are the most common technical reasons bet placement fails, drawn from real-world operation of high-volume wagering platforms.
1. Too many synchronous dependencies
The fastest way to break bet placement is to make it depend synchronously on everything.
Common offenders include:
Identity and session validation
KYC / jurisdiction checks
Wallet balance and limits
Market state
Pricing confirmation
Trading approval
Promotions / bonuses
Payments (yes, people still do this)
Every synchronous hop adds latency and multiplies failure probability.
Under peak load, even a small slowdown in one dependency can push the entire request over its latency budget.
What the system is telling you:
The bet placement path should be short, deterministic, and aggressively bounded.
Anything that doesn’t need to be synchronous shouldn’t be.
2. Market state churn and race conditions
Markets move. Prices change. Selections suspend and re-open.
Feed updates arrive in bursts.
If bet placement:
Reads market state from multiple sources
Relies on stale caches without invalidation
Doesn’t enforce price staleness windows
…you get classic race conditions, namely:
Bets accepted on suspended markets
Bets rejected even though the UI showed availability
Duplicate retries hitting different market states
Failure mode: Customers see “technical error” or inconsistent rejections during peak trading.
What the system is telling you:
Market state must be versioned, cached close to placement, and validated with explicit tolerances (“price valid for X ms”).
3. Wallet design flaws (the silent killer)
Wallet issues are typically responsible for a disproportionate number of bet placement failures.
Typical problems that I’ve seen include:
No true reservation/hold model
Weak or missing idempotency
Balance checks separated from debits
Ledger writes mixed with business logic (this one is classic, you’d be surprised how any times it happens!)
Under concurrency, this leads to:
Double spends
Phantom insufficient-funds errors
Reconciliation nightmares after recovery
What the system is telling you:
Wallets must be boring, deterministic, and mathematically correct.
If your wallet logic is clever, it’s probably broken when you have high traffic. Or even when you don’t!
4. Trading decisions that don’t degrade gracefully
Trading systems often assume they’ll always respond quickly.
Newsflash: they won’t.
When trading:
Times out
Is under heavy load
Is partially unavailable
…bet placement frequently has no clear fallback. The result can be long timeouts that cascade back to the edge, rather than fast, explainable rejections.
Better behaviourpatterns include:
Explicit time budgets for trading decisions
Default reject on timeout with a clear reason code
Rapid market suspension when instability is detected
What the system is telling you:
A fast reject is better than a slow maybe.
5. Retry storms and idempotency gaps
During peak events, clients retry.
Load balancers retry.
Upstream services retry.
If bet placement:
Doesn’t enforce idempotency keys
Treats retries as new requests
Emits side effects before commit
…you get duplicate bets, duplicate wallet postings, or corrupted state.
What the system is telling you:
Idempotency is not an optimisation.
It’s a core correctness requirement.
6. Overloaded databases and hidden coupling
Bet placement often looks stateless at the API level, but is tightly coupled to:
Shared databases
Hot tables (balances, open bets)
Lock-heavy schemas
Under load, lock contention silently destroys throughput, leading to sudden, nonlinear failure.
What the system is telling you:
If throughput collapses before CPU does, you have a data contention problem, not a scaling problem.
7. Poor observability in the critical path
When bet placement fails and you can’t answer:
Where did the time go?
Which dependency failed?
Was this a reject, a timeout, or a partial commit?
…you lose the ability to respond confidently during incidents.
This leads to:
Over-suspension (“turn everything off”)
Over-engineering after the fact
Loss of trust from trading and operations
What the system is telling you:
If you can’t see it under pressure, you can’t control it.
The pattern behind all failures
Nearly all bet placement failures share one root cause:
The system is trying to do too much, too synchronously, with unclear ownership of outcomes.
Healthy bet placement services are:
Thin at the edge, thick in the domain
Ruthless about timeouts and failure modes
Explicit about what they will and will not guarantee
A better mental model
Think of bet placement as this:
A transaction coordinator, not a workflow engine
A risk gate, not a business logic dumping ground
A trust boundary, not an integration hub
If something feels awkward to implement in bet placement, that’s usually your architecture asking for a boundary to be moved.
Final thought
When bet placement fails, teams often reach for more caching, more hardware, or more retries.
Rarely do those fixes address the underlying problem.
The real work is harder: simplifying the synchronous path, tightening ownership, and designing for rejection as a first-class outcome.
Platforms that get this right don’t just place bets faster—they fail more gracefully, recover more predictably, and earn trust when it matters most.
The L1 / L2 / L3 support model is one of the most widely adopted – and most poorly understood – operating patterns in modern technology organisations.
On paper, it looks really clean and rational: first-line support handles intake, second-line investigates, third-line engineers fix root causes.
Escalation is orderly. Responsibilities are clear. Everyone knows their lane.
In practice, many organisations discover the uncomfortable truth: without clear ownership, L1/L2/L3 doesn’t reduce incidents: it completely institutionalises confusion.
After years of operating platforms in regulated, high-availability environments, I’ve seen the same failure modes repeat with remarkable consistency. The issue is rarely the model itself. It’s the absence of real accountability at the seams.
The illusion of escalation
The biggest misconception is that escalation equals ownership.
In weak implementations, an incident “moves up the stack” without ever truly belonging to anyone. L1 logs the ticket and hands it off. L2 adds commentary and escalates. L3 investigates when time permits.
Meanwhile, the system remains degraded, customers are impacted, and no single individual feels responsible for resolution.
Escalation becomes a mechanism for risk transfer, not problem solving.
When nobody owns the outcome end-to-end – and I mean technical fix, communication, and crucially learning – the model devolves into a queueing system that optimises for local convenience rather than global reliability.
L1 without ownership becomes a call centre
L1 is often positioned as “just intake”: logging tickets, resetting passwords, acknowledging alerts. But when L1 lacks clear ownership boundaries, it becomes little more than a message relay.
Effective L1 teams do more than triage.
They:
Own initial diagnosis, not just categorisation
Apply runbooks with authority, not fear of escalation
Decide whether an issue is noise, delay, or degradation
Without ownership, L1 staff are incentivised to escalate early and often—because escalation feels safe. The result is alert fatigue upstream and a complete lack of signal discipline.
L2 becomes a dumping ground
L2 is where many models quietly collapse.
You’ve seen it. I’ve seen it. We’ve all rolled our eyes, collectively and individually, and groaned.
In theory, L2 provides deeper technical investigation and remediation within defined limits. In reality, L2 often inherits ambiguity: unclear service boundaries, incomplete documentation, and no authority to make changes.
When L2 doesn’t own specific systems or outcomes, it becomes a holding pen for unresolved problems. Tickets stall. Context is lost.
Engineers re-diagnose the same issue repeatedly because nobody is accountable for closing the loop.
This is how mean time to resolution quietly stretches from minutes to hours: without anyone feeling explicitly at fault.
L3 without ownership breeds resentment
L3 teams (usually product or platform engineers) are where the real fixes happen.
But when ownership isn’t explicit, L3 becomes reactive and defensive.
Common symptoms that I’ve seen usually include:
Engineers pulled into incidents with no context or priority clarity
Fixes made under pressure without time for proper remediation
Repeated incidents caused by known issues that never get scheduled work
From the engineer’s perspective, L3 becomes an interruption tax.
From the business’s perspective, it’s a black box.
Neither side is well served.
Everyone loses!
The real failure: nobody owns the service
The core problem isn’t the number of layers – it’s the absence of service ownership.
In healthy organisations:
Every system has a clearly identified owner (individual or team)
That owner is accountable for availability, performance, and support outcomes
L1/L2/L3 act as capability layers, not responsibility boundaries
To be clear on this, and many people make this mistake – ownership does not mean “doing everything yourself”!
It means being accountable for:
Decision-making during incidents
Trade-offs between speed, risk, and correctness
Ensuring learning happens after recovery
Without this, post-incident reviews become blame-avoidance exercises rather than improvement mechanisms.
What works instead
Successful support models invert the usual thinking:
Service ownership first – Define who owns each system. Make that ownership visible and unambiguous.
L1 and L2 operate under delegated authority – Runbooks, thresholds, and decision rights matter more than escalation paths.
L3 owns root cause, not just fixes – If an issue repeats, it’s an ownership failure—not a support failure.
Incidents have a named incident owner – One person is accountable for coordination, communication, and closure, regardless of where the fix lands.
Support is a feedback loop, not a firewall – Good support improves the system. Bad support merely absorbs pain.
The uncomfortable truth
L1/L2/L3 models don’t fail because they’re outdated. They fail because they’re often implemented as organisational insulation, designed to protect teams from responsibility rather than enabling reliable delivery and clear learnings.
Here’s the truth – true ownership is uncomfortable.
It forces clarity.
It exposes weak interfaces, poor documentation, and brittle systems.
But it’s also the only thing that turns support from a cost centre into a reliability engine.
If your support model feels busy but ineffective, the question isn’t whether you need another layer – it’s whether anyone truly owns the outcome.
It’s almost one year since my old employers got raided. Luckily I’d been away from them for a long time, and I do feel sorry for many of the innocent people who lost their jobs. It must have been awful and a terrible shock to them.
Obviously, it should be very much clear to everyone that I’ve no involvement in any of this investigation, and I’ve offered my services to the authorities to help them in any way possible, should they need it. I’m sure you knew this already, but it’s just worth being clear on it!
There is a reason that King and co are no longer operating and under police investigation and though I won’t speculate except where the facts permit, I’ll pretty much rely on the facts contained within the following judgment in Chinese, as shown below.
The above is a snippet of a judgment from a chinese court that links King Gaming Isle of Man and Manx Internet Commerce (MIC) to what seems to have been ongoing and massive scamming activity conducted by at least six individuals who were working for various teams within King and MIC on the island.
They all admit to carrying out these scam activities, having been relocated from the Philippines on visas by the company, carrying on their behaviour on the Isle of Man.
These people engaged in activities that scammed and cheated people out of amounts in the millions, according to the judgment.
What is interesting from this judgment is that they all appeared to work in separate teams, suggesting strongly that the overall fraud headline figure could very well be considerably higher.
The evidence that I’ve seen from other sources including the BBC strongly suggests upwards of 100 staff engaged in this sort of activity.
There are more sources in mandarin that I’ve seen that are much more explicit on what was going on, but I won’t link them here – again, for obvious reasons.
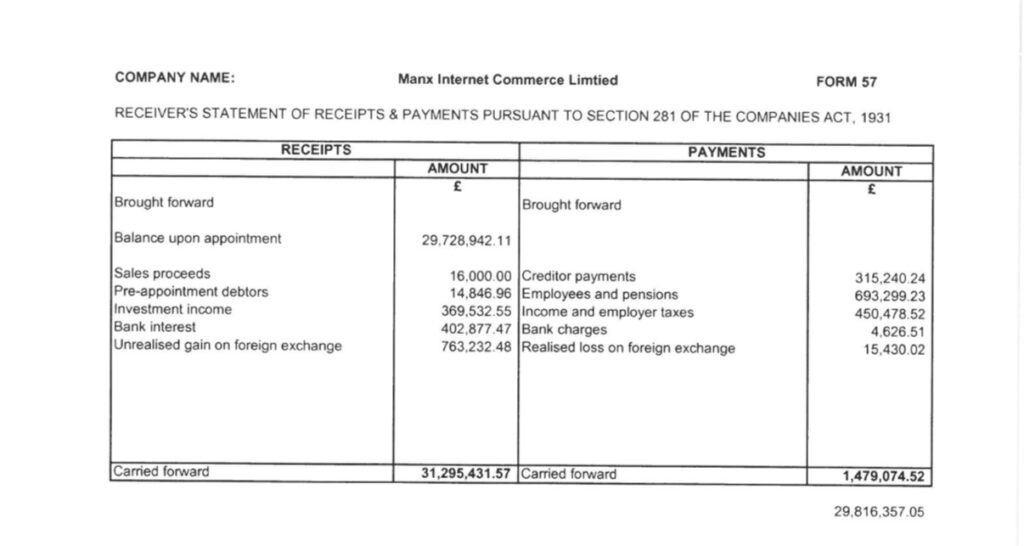
The public updates from the official Receiver that King and MIC had around 65 million and 30 million in their bank accounts gives more clarity to the overall picture, as shown below.
The facts don’t lie!
The translation of the judgment is rough but very much clear on what took place.
According to this BBC article, they were based first at the Seaview Hotel and then latterly this office space at Howard Pearson house in Douglas.
Actually, right next to where the new HQ was going to be!
Some more information that has emerged is about the ultimate ownership of the company.
Above and pictured is “Bill Morgan” aka Lingfei Liang. UBO of King Gaming (and other companies including Manx Internet Commerce / Champion Tech) and the boss that was referred to in the judgment. I’ve never formally met him, but I did see him at our stand in the Philippines in 2019 at an industry show.
This above is Yanhao (Kevin) Zhu. Former boss of the Isle of Man “operation”, and former director of Champion Tech. He was my boss.
He’d apparently worked in “fintech” (ahem) for Morgan for a number of years, and as such was a trusted lieutenant.
These guys will not like being named or pictured, I won’t be popular for doing so. I’m not exactly stressed out about that, if I’m honest.
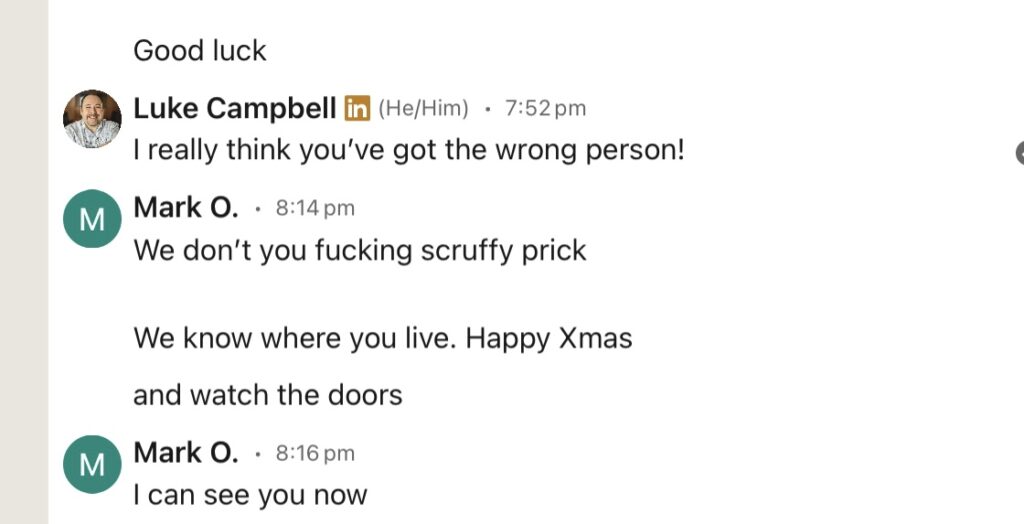
These facts above notwithstanding, some people ( with a grudge) are clearly peeved that, not only did I win an employment tribunal case (*) on all grounds, they’re also clearly jealous that I left earlier than them, judging from their colourful messages:
…these are some of the lovely message I got from a lovely chap called “Mark O”, who I’d imagine is upset that King Gaming got closed down.
If everything that is being suggested is true, then I certainly won’t lose any sleep over being harassed by the very people who clearly allowed this stuff to happen on their watch.
I can easily refute any spurious crap they might come up with, and I’m not going to give their rubbish the light of day: these sorts of things simply don’t deserve that type of oxygen!
As directors and officers, ultimately they had clear responsibilities and oversight – and it is on them to justify their actions or inaction, whichever is true.
So – they are the ones who should be ashamed of themselves and they ought to be angry.
….at each otherand themselves!
The more I’ve heard about what happened, the more I’m utterly sickened, disgusted and horrified.
Let’s see what happens from here, but I think it’s fair to say that we all expect that, where appropriate, justice will be served once any process has run its course.
(*) I was one of the first ones if not the first to raise concerns about working conditions at King, working til 3am and then back at your desk at 8am or your visa cancelled doesn’t sound like reasonable working conditions…..see here for more.